

We introduce here two successful ideas that were used to modify attributes of images, such as their style, while keeping their content: Neural Style Transfer and CycleGAN.
Neural Style Transfer for images
In 2015, Leon A. Gatys et al. published the first Neural Algorithm of Artistic Style. Their methods was able to output an image whose content is the same as the first input image’s content, with the style of a second input image. See the photograph below, painted in the style of famous artists.

Example of a photograph painted with famous painters’ styles. Figure from Gatys et al.
To paint a picture in a specific style, the authors relied on a pre-trained deep Convolutional Neural Network (CNN). Basically, they synthesized the output image (randomly initialized) by minimizing the total objective function L, where L(output, input1, input2) = Lcontent(output, input1) + Lstyle(output, input2). Lcontent (respectively Lstyle) measures the distance of content (respectively style) between the output image and the first (respectively second) input image.
If you wonder how Lcontent and Lstyle are computed, consider the content and the style of an image (input or output) derive from its representation at an internal layer of the pre-trained CNN (the Gram matrix is used for computing the style of an image but we won’t go into details here). The distance of content is an error between the input’s content and the ouput’s content. Likewise, the distance of style is also an error.
The output image is updated at each gradient descent step by receiving the backpropagated content and style errors in L (backpropagated all the way through the pre-trained model). Here, only the image is updated, not the model’s weights; there is no “training phase” in the sense that the model is never updated but we can’t talk of “unsupervised learning” since the CNN was pre-trained.
For more information, please refer to the original publication or check this great blog post for a quick review and reimplementation.
CycleGAN: Image-to-Image Translation without paired training data
Neural Style Transfer was a very good technic to transfer a photograph into a painter’s style mode. However it fails to transfer a painting to a photorealistic mode. Actually, Image-to-Image translation is more general than painting a picture in a specific style. Can we learn a mapping between specific local attributes of two sets of images? For instance can we go beyond the painters’ style immitations and transform apples into oranges or even horses into zebras?
This is what Jun-Yan Zhu et al. did with their model called CycleGAN. As CycleGAN applies Image-to-Image translation more generally than style transfer, we’ll use the phrase “attribute transfer” (an attribute can be the style of a painter but the it can be more general).

Examples of images translated with other attributes. Figure from Zhu et al.
CycleGAN differs from Neural Style Transfer in 3 ways:
- It learns a mapping between two (unpaired) sets of images
- It involves an adversarial loss.
- It introduces the cycle consistency loss.
First CycleGAN is an unsupervised learning method. This means it doesn’t need any correspondance between paired images with the exact same content (e.g. a pair of images with three Equidae in a specific position with a specific background) and different attributes (on the first image the Equidae are horses while on the second they are zebras). For training, CycleGAN only needs two collections of images, each collection having a known specific style (e.g. a collection of horses and a collection of zebras). This learned mapping allows for generating translated images faster than with Neural Style Transfer since the translation only involves fastforward inference and no backpropagation. Moreover, this enabled authors to apply CycleGAN to videos.
How to learn such a mapping?
Adversarial loss
As indicated by its name, CycleGAN involves an adversarial loss inspired by Generative Adversarial Networks (GANs). A GAN setting consists in a first neural network (the generator) trying to generate images from a source collection to a destination collection while a second neural network (the discriminator) tries to distinguish images that actually belong to the desination collection. In Image-to-Image translation, we are interested in translating attributes in both ways (source can be seen as destination and vice versa), therefore we need two generators (one for attribute1 -> attribute2 and one for attribute2 -> attribute1) and two discriminators (one for attribute1 and one for attribute2).
Discriminators are CNNs and generators are made of a convolutional encoder layers, ResNet transformer blocks and deconvolutional decoder layers.
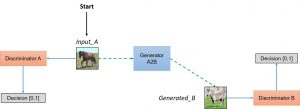

Simplified view of the GAN loss in CycleGAN. Figure adapted from hardikbansal.github.io
Is an adversarial loss enough? Not if the generator is too large since it will be able to map an input collection image with attribute1 to any random permutation of images with attribute2. This is where the cycle consistency loss will play its regularization role by constraining the “round trip” image translation to be close to the source image.
Cycle consistency loss
Actually this idea was inspired from… text translation! As shown with humor by Mark Twain in 1903, translating a source sentence from one source language to a target language and then translating the translated sentence back from the target language to the source language should give the source sentence. Examples show that litteral translations can be funny:
English source: “It’s freezing cold.”
Correct French translation: “Il fait un froid de canard.”
Litteral English back-translation: “It is a cold of duck.”
English source: “To take French leave.”
Correct French translation: “Filer à l’anglaise.”
Litteral English back-translation: “To take English leave.”
Consequently, CycleGAN introduces the cycle consistency loss as being the distance between the source image and the translation from destination to source of its translation from source to destination.
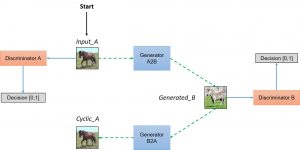

Simplified view of the GAN loss and the cycle consistency loss in CycleGAN. Figure from hardikbansal.github.io
The CycleGAN model can then be trained by optimizing the sum of the adversarial loss and the cycle consistency loss:
L(GA2B, GB2A, DA, DB) = LGAN(GA2B, DB, A, B) + LGAN(GB2A, DA, B, A) + λLcyc(GA2B, GB2A)
where LGAN(G, D, X, Y) = 𝔼y~pdata(y)[log(D(y))] + 𝔼x~pdata(x)[log(1-D(G(x)))]
and Lcyc(GA2B, GB2A) = 𝔼x~pdata(x)[∥GB2A(GA2B(x))-x∥1] + 𝔼y~pdata(y)[∥GA2B(GB2A(y))-y∥1]
The optimization is G*A2B, G*B2A = argmin(GA2B, GB2A) max(DA, DB) L(GA2B, GB2A, DA, DB)
Comparing CycleGAN with Neural Style Transfer
As you can see below, CycleGAN manages to transfer local attributes (apples to oranges, horses to zebras, painting to realistic photograph) where Neural Style Transfer fails.

Comparison between Neural Style Transfer and CycleGAN. First column is the input, columns 2 to 4 are the output of Neural Style Transfer (or variations) and column 5 is the output of CycleGAN. Figure from Zhu et al.
What did we learn from Image-to-Image translation?
- Neural style transfer synthesizes an image from a blank canvas by imitating the content of the first image input and the style of the second image input. This is enabled because internal layers of pre-trained CNNs capture features that can effectively provides accurate “content” and “style” information.
- CycleGAN learns a mapping between two collections of images, each with a specific attributes (horses vs zebras, Monet’s paintings vs photographs). The cycle consistency loss is essential to ensure that the content is not altered.
Can technics of Image-to-Image translation be applied to Text-to-Text translation ?
There are several reasons why Image-to-Image Neural Style transfer won’t work with text. I think the discrete and ambiguous nature of text are the main issues. Except in very specific edge cases, a visual feature is often clear and unambiguous, whereas words convey so many semantic features depending on the context; outputing general and high-level features of sentences (like their content or style) just by looking at an internal convolutional layer of a CNN’s pretrained on a text classification task seems impossible.
“The common misconception is that language has to do with words and what they mean.
It doesn’t.
It has to do with people and what they mean.”Herbert H. Clark & Michael F. Schober, 1992
In Multiple-Attribute Text Rewriting, Lample et al. explain why CycleGAN was not directly applied to text: “Unfortunately, the discrete nature of the sentence generation process makes it difficult to apply to text techniques such as cycle consistency or adversarial training. For instance, the latter requires methods such as REINFORCE or approximating the output softmax layer with a tunable temperature, all of which tend to be slow, unstable and hard to tune in practice. Moreover, all these studies control a single attribute (e.g. swapping positive and negative sentiment).”